演示视频
是否包含论文文档
是
技术描述
开发工具: Pycharm
后端框架: Python
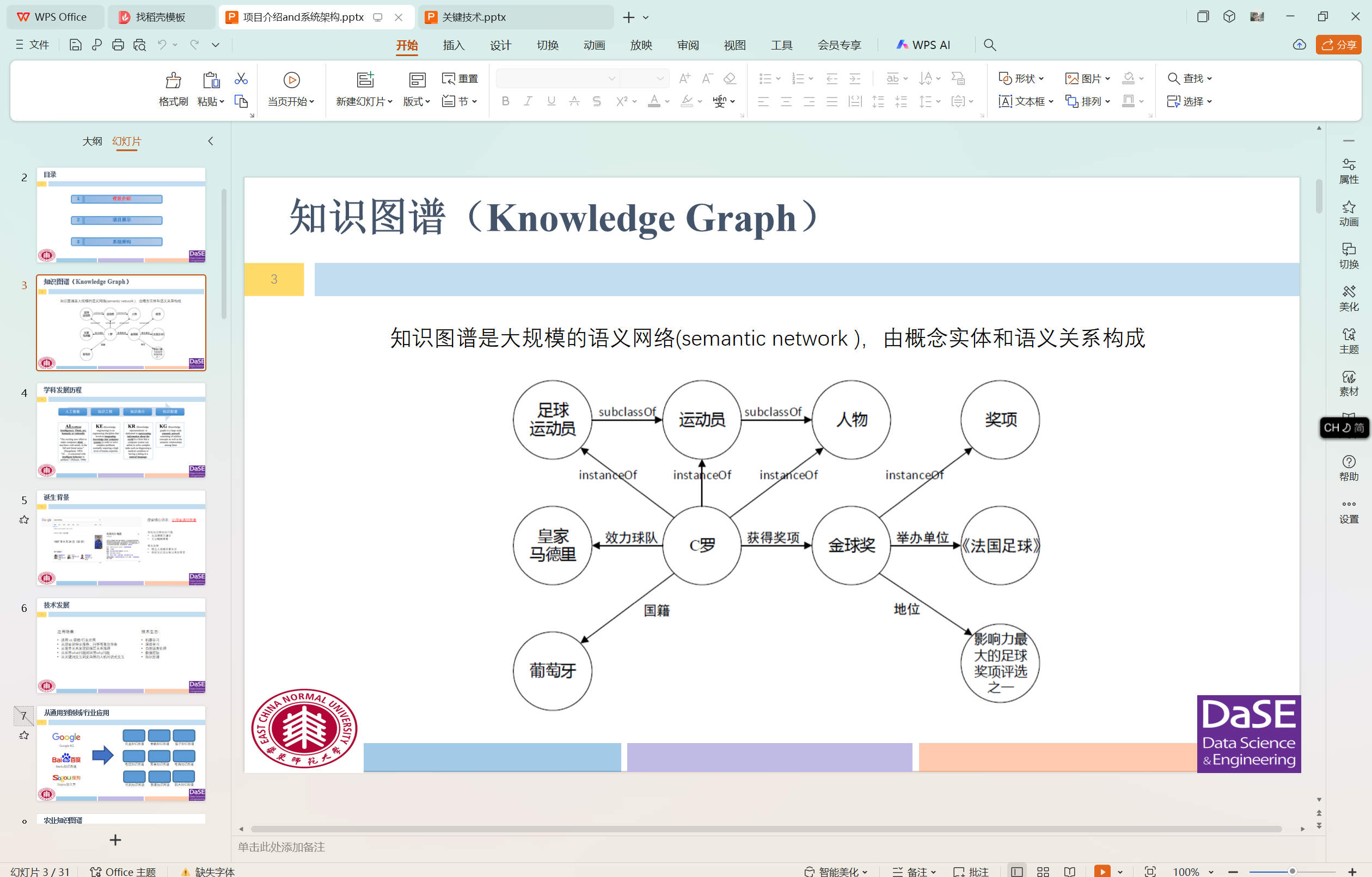
项目截图描述
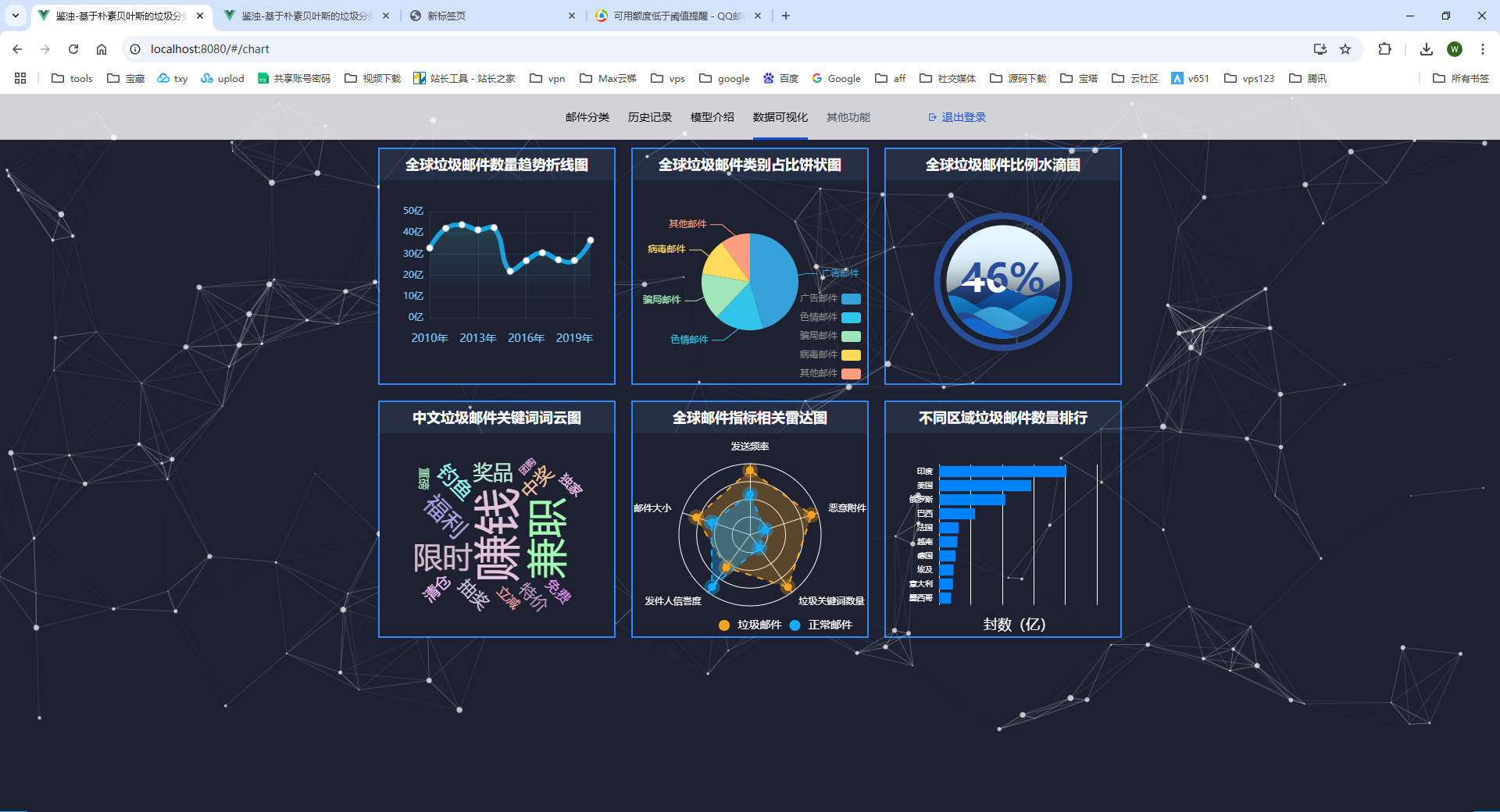
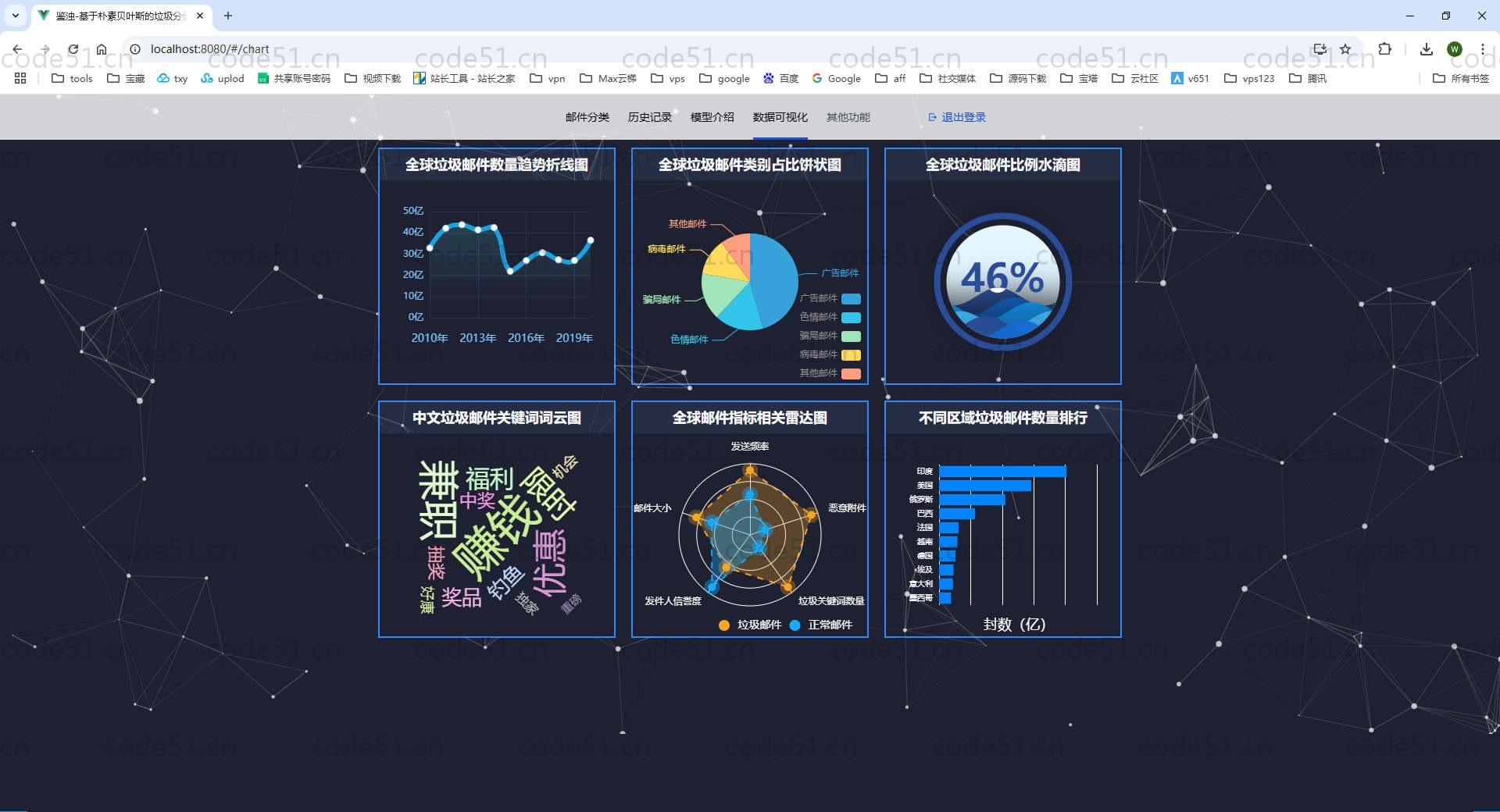
部分截图
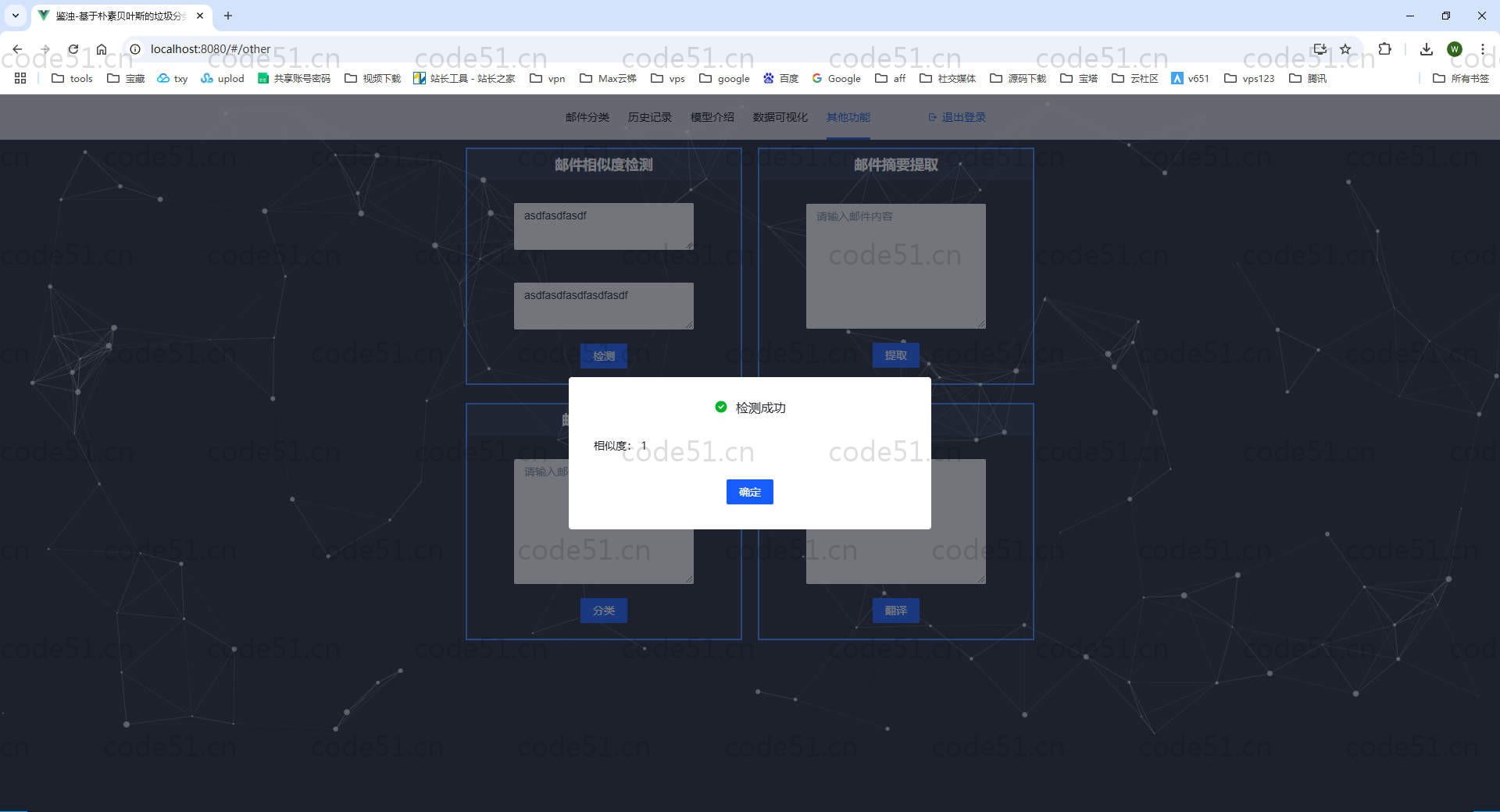
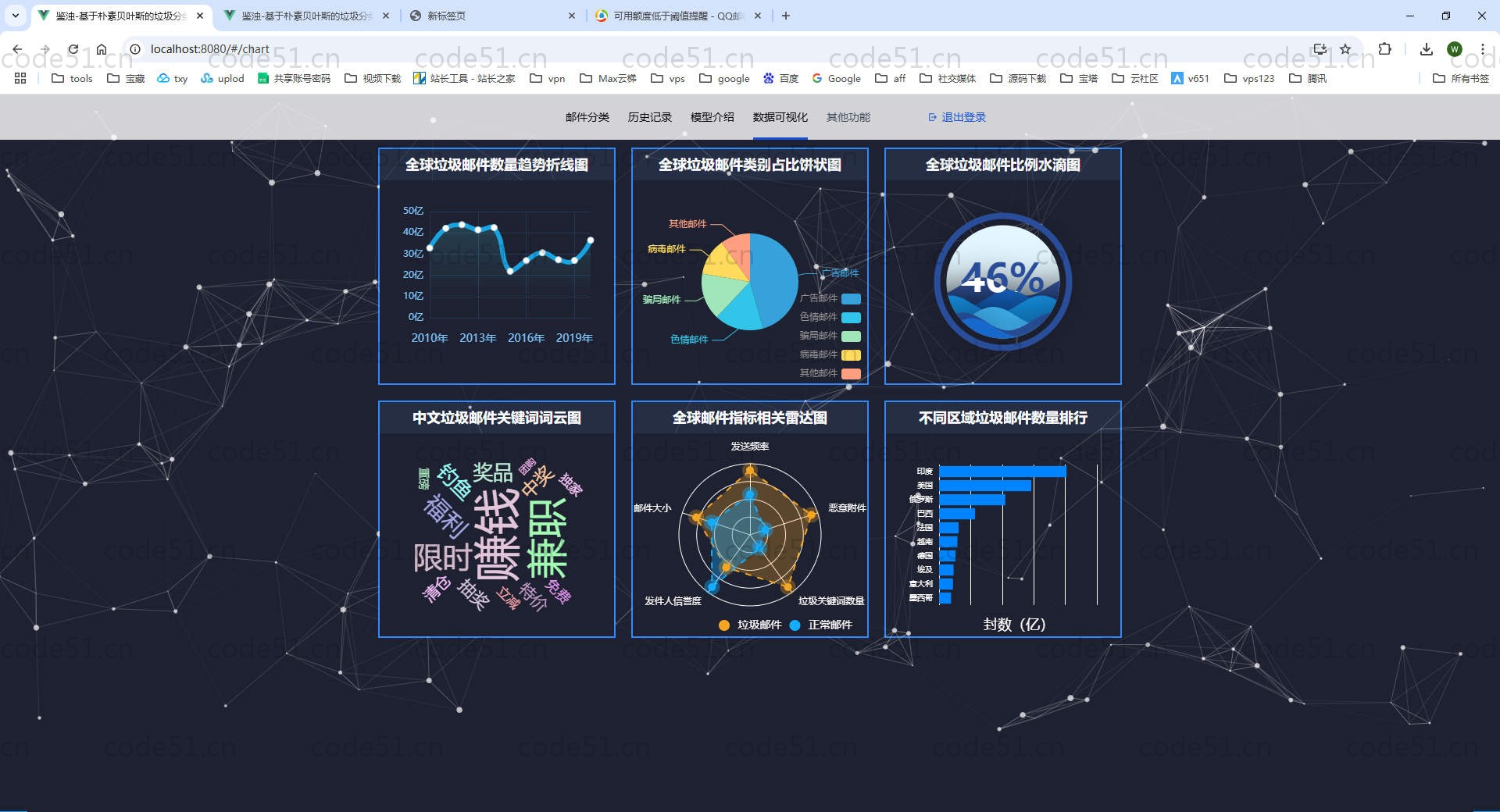

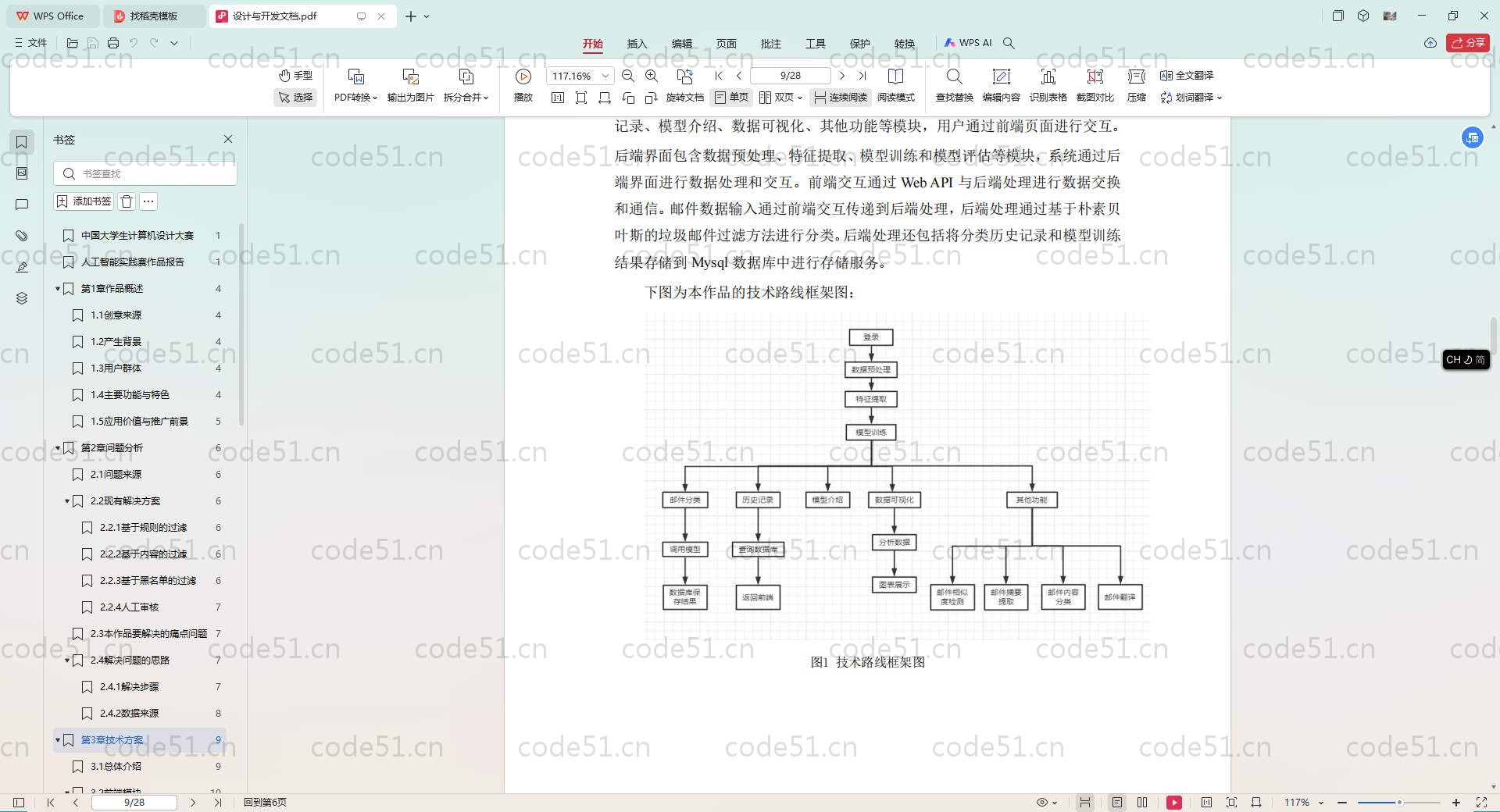



详细描述
基于Python的朴素贝叶斯的垃圾邮件分类系统(含文档),
基于Python的朴素贝叶斯的垃圾邮件分类系统(含文档),包含数据集,可再次训练,预测,训练的模型。
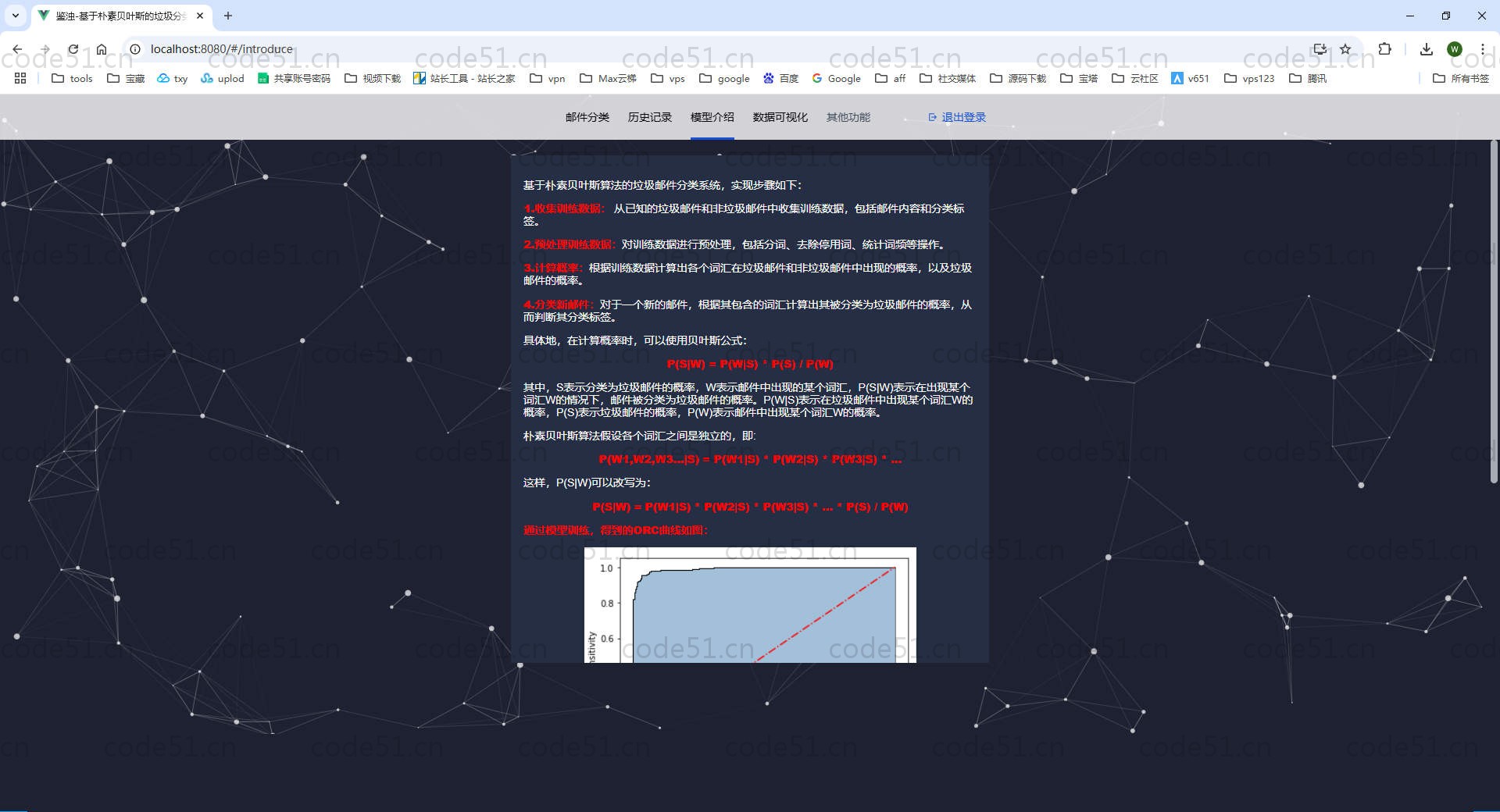
基于朴素贝叶斯算法的垃圾邮件分类系统,实现步骤如下:
1.收集训练数据: 从已知的垃圾邮件和非垃圾邮件中收集训练数据,包括邮件内容和分类标签。
2.预处理训练数据:对训练数据进行预处理,包括分词、去除停用词、统计词频等操作。
3.计算概率:根据训练数据计算出各个词汇在垃圾邮件和非垃圾邮件中出现的概率,以及垃圾邮件的概率。
4.分类新邮件:对于一个新的邮件,根据其包含的词汇计算出其被分类为垃圾邮件的概率,从而判断其分类标签。
具体地,在计算概率时,可以使用贝叶斯公式:
P(S|W) = P(W|S) * P(S) / P(W)
其中,S表示分类为垃圾邮件的概率,W表示邮件中出现的某个词汇,P(S|W)表示在出现某个词汇W的情况下,邮件被分类为垃圾邮件的概率。P(W|S)表示在垃圾邮件中出现某个词汇W的概率,P(S)表示垃圾邮件的概率,P(W)表示邮件中出现某个词汇W的概率。
朴素贝叶斯算法假设各个词汇之间是独立的,即:
P(W1,W2,W3...|S) = P(W1|S) * P(W2|S) * P(W3|S) * ...
这样,P(S|W)可以改写为:
P(S|W) = P(W1|S) * P(W2|S) * P(W3|S) * ... * P(S) / P(W)
通过模型训练,得到的ORC曲线如图:
在ROC曲线中,横坐标为FPR,表示被错误地分类为正例的负例样本所占总负例样本的比例。纵坐标为TPR,表示被正确地分类为正例的正例样本所占总正例样本的比例。
从图中可见,ROC曲线靠近左上角,说明分类器的性能越好,因为此时TPR高、FPR低。
ROC曲线下的面积(AUC)被称为曲线下面积,是一个用于评估分类器性能的重要指标。AUC的取值范围在0.5到1之间。
从图中可见,AUC=0.99,接近1表示分类器的性能极好。
分享地址
复制地址转发给你的小伙伴: https://code99.top/3682.html